
Teradata 并行数据库架构
Jun 06, 2014

Teradata 在整体上是按 shared-nothing 架构体系进行组织的,每个节点都是 SMP 结构的单机,多个节点一起构成一个 MPP 系统。
一、并行数据库架构
并行数据库要求尽可能的去并行执行数据库操作,从而提高性能。在并行计算体系结构实现中有很多可选的体系结构。包括,
- share-memory:多个 CPU 共享同一片内存,CPU 之间通过内部通讯机制(interconnection network)进行通讯;
- share-disk:每一个 CPU 使用自己的私有内存区域,通过内部通讯机制直接访问所有磁盘系统;
- share-nothing:每一个 CPU 都有私有内存区域和私有磁盘空间,而且 2 个 CPU 不能访问相同磁盘空间,CPU 之间的通讯通过网络连接。
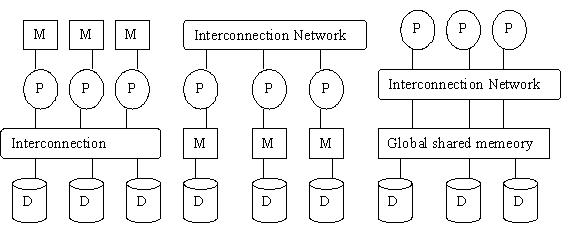
从左至右分别是 share-disk, share-nothing 和 share-memory 架构。
注:Oracle Real Application Clusters(RAC) 是 share-disk 架构,Teradata和 DB2 是share-nothing 架构。
二、Teradata 数据仓库架构
2.1. 逻辑架构
2.1.1. Teradata 的组成
Teradata 的主要构件有,
【解析引擎(Parsing Engines,PE)】
主要用于进行客户系统(通常指使用 Teradata 数据库的应用程序的 SQL 请求)和存取模块处理器之间的通讯和交互。主要的功能包括会话管理(session control),SQL 语句的解析、优化、查询步骤的生成和分发请求到对应的 AMP,并行化预处理和返回查询结果。一个节点上通常只有一个或两个 PE 在工作。
【消息传递层(Message Passing Layer,MPL)】
允许 PEs 和 AMPs 相互通信,链接多个节点,在逻辑上使之如同一个节点一样运行。
【存取模块处理器(Access Module Processor,AMP)】
这是 Teradata 数据库的关键进程,用于处理所有与数据有关的文件系统的操作任务,是 Teradata 数据库 share-nothing 架构的核心表现。通常情况下,一个节点上会有多个AMP 在工作,每个 AMP 拥有并管理本身的存储空间,负责文件系统上不同的、固定的数据的存取操作。
【虚拟磁盘(Virtual Disk,VDisk)】
典型的 Teradata 大规模并行处理系统(Massive Parallel Processing,MPP)的数据存储都是以磁盘阵列(disk arrays)的形式实现的,在物理结构上表现为一个个存放于标准磁盘阵列柜中的磁盘阵列模块。Teradata 系统中的每个 AMP 在处理数据存储时,会根据一种哈希算法把不同的数据均勻地分散存储到磁盘阵列中的不同的磁盘上,这样,在逻辑上我们就把磁盘阵列中不同磁盘上存储着的那些由同一个 AMP 负责存储和维护的数据合并在一起,就像它们在一个磁盘上一样,这就是虚拟磁盘。
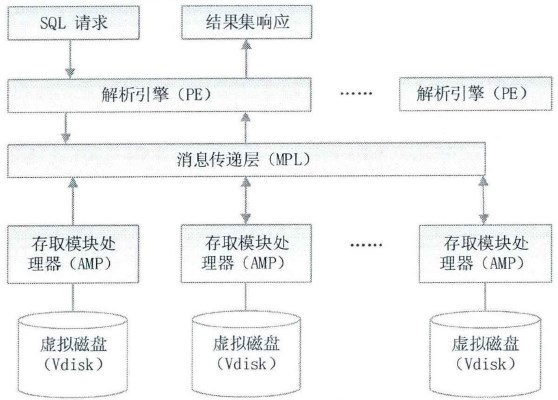
2.1.2. 组件间的交互
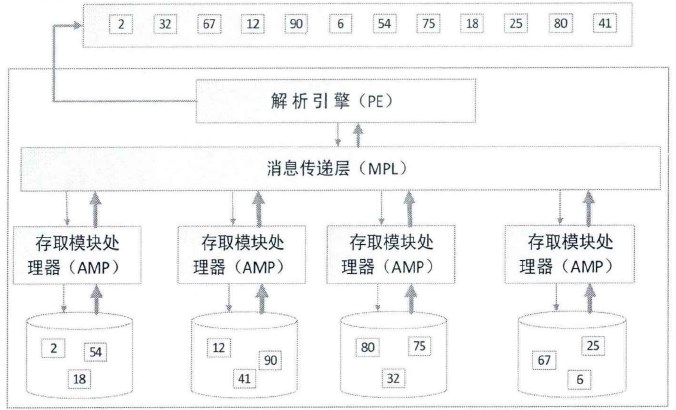
每当执行 select 请求的时候,PE 发送读取一行或多行记录的请求到 MPL,MPL 确保每个 AMP 的可用性,AMP 使用并行方式访问本身管理的存储空间,并查找符合查询条件的数据记录行。当每个 AMP 把查询到的记录返回到 MPL 之后,MPL 需要对每个 AMP 返回的记录整合,传递到 PE,PE 将最终结果返回给客服端,呈献给最终查询的用户。
2.2. 物理架构
2.2.1. 硬件架构
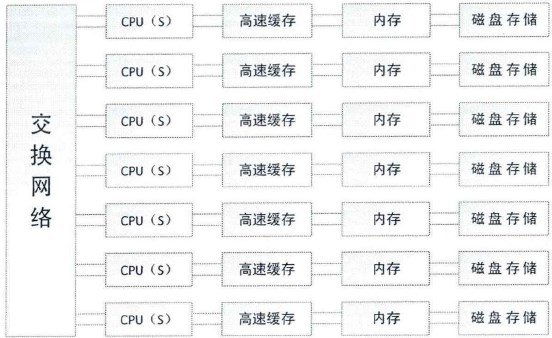
在硬件方面,MPP 服务器是由多个对称多处理器(Symmetric Multi-Processor,SMP)通过一定得节点互联网连接,来协同工作和完成相同的任务。在用户的角度来看是一个系统。
MPP 服务器架构的特点是由多个 SMP 服务器(每个 SMP 服务器被称作「节点(node)」)通过节点互联网络连接而成。每个 SMP 服务器拥有自己的 CPU、内存以及存储空间。SMP 之间是相互独立的、没有资源的共享,这就是 Teradata 数据库架构的 sharing-nothing 架构。
2.2.2. 软件架构
在软件方面,主要有,
【查询并行(query 并行)】
这种并行处理是基于哈希(hash)数据分配机制实现的。每个 AMP 都是一个虚拟处理器(VPROC),各自独立负责一部分数据的处理,相互之间没有关系,每个节点一般配置 4 至 16 个这样的 VPROC。所有关系运算如表的搜索、索引检索、投影、选择、联接、聚集、排序等都是由各个 VPROC 并行进行的。
【步内并行(within-a-step 并行)】
一个 SQL 查询进入系统后,首先由优化器进行优化处理,分解成一些小的步骤,然后再分发给各 VPROC 进行处理。
一个步骤可能非常简单,如“搜索一个表并返回结果”;也可能非常复杂,如“按照某条件搜索两个表,然后联接,结果投影到某几个列,对它们加和(sum)后返回结果”。像这种复杂查询将处理多个关系运算,每个关系运算在一个 VPROC 内将启动多个进程来实现并行处理,称为步内并行。
【多步并行(multi-step 并行)】
上面说过,一个 SQL 被分解成多个小的步骤,这些步骤的执行将同时进行,称为多步并行。优化器分解一个 SQL 查询请求的原则是尽可能使各步独立。在目前所有的 DBMS 产品中,只有 Teradata 实现了多步并行。
三、使用 VMware 安装 Teradata Express
如果希望尝试一下 Teradata,可以在 PC 机上安装 Teradata Express 版。
以下是安装步骤:
-
确认计算机是 64 位并且支持 Intel VT-x,内存 4GB 以上,硬盘剩余空间 60GB 以上
-
需要在 BIOS 中将 Intel VT-x 打开(注:修改完 BIOS 后需要断电重新启动才能生效)
-
下载 VMware Player,并安装
-
下载 Teradata Express for VMWare,解压缩到一个目录中(例如,
D:\virtual-machines\TDExpress14.10.01_Sles11_40GB) -
打开 VMware Player,选择「Open A Virtual Machine」,选择 vmx 文件(例如,
TDExpress14.10.01_Sles11.vmx) -
按照默认选项启动 Teradata Express 虚拟机
-
启动完毕后会进入 Gnome 桌面,登录名
root,密码root,VMware Player 可能会提示更新 VMware Tools -
等待 VMware Tools 下载完毕,挂载CDROM
mount /dev/cdrom /mnt/cdrom
- 将 VMware Tools 文件从 CDROM 拷贝到临时目录下
cp /mnt/cdrom/* /tmp/vmware-tools-install
- 解除 CDROM 挂载
unmount /dev/cdrom
- 解压缩 VMware Tools
tar zxvf <vmware-tools-package>
- 安装VMWare Tools,按照提示一步步执行
cd vmware-tools-distrib
vmware-install.pl
- 重新启动,进入 Gnome 桌面
# reboot
shutdown -h now
- 启动 BTEQ
bteq
- 登录仓库,密码:
dbc(注:命令前需要有一个点)
.logon 127.0.0.1/dbc
- 如果登录不成功出现提示「RDBMS CRASHED OR SESSIONS RESET. RECOVERY IN PROGRESS」,原因可能是数据仓库未启动,启动数据仓库
/etc/init.d/tpa stop
/etc/init.d/tpa start
-
成功登录后,提示「Logon successfully completed」
-
测试是否可以执行 SQL 语句
select * from dbcinfo
- 退出 BTEQ
.quit
-
修改
/etc/inittab,将默认启动级别从 5 改为 3,重启系统 -
启动数据仓库
/etc/init.d/tpa start
-
使用客户端工具远程连接数据仓库,首先使用
ifconfig查看数据仓库 IP 地址 -
连接成功后,测试是否可以执行 SQL 语句
select * from dbcinfo
- 创建用户
CREATE user vmtest AS password=vmtest perm=524288000 spool=524288000;
- 创建表
CREATE SET TABLE vmtest.test,
NO FALLBACK ,
NO BEFORE JOURNAL,
NO AFTER JOURNAL,
CHECKSUM = DEFAULT (
Test_field1 INTEGER,
Test_field2 INTEGER)
PRIMARY INDEX ( Test_field1 );
- 在
/tmp下创建test.csv文件,文件内容如下(注:最后不要有回车换行(空行))
1, 4
2, 5
3, 6
- 装载CSV文件
/opt/teradata/client/14.10/tbuild/bin/tdload -h 127.0.0.1 -u vmtest -p vmtest -f test.csv -t test
- 装载成功后,在客户端查询得到结果
sel * from vmtest.test
- 如果查询说 test 表已经被 lock,则应该是装载数据出错,修改 csv 文件,重新执行一遍即可。